
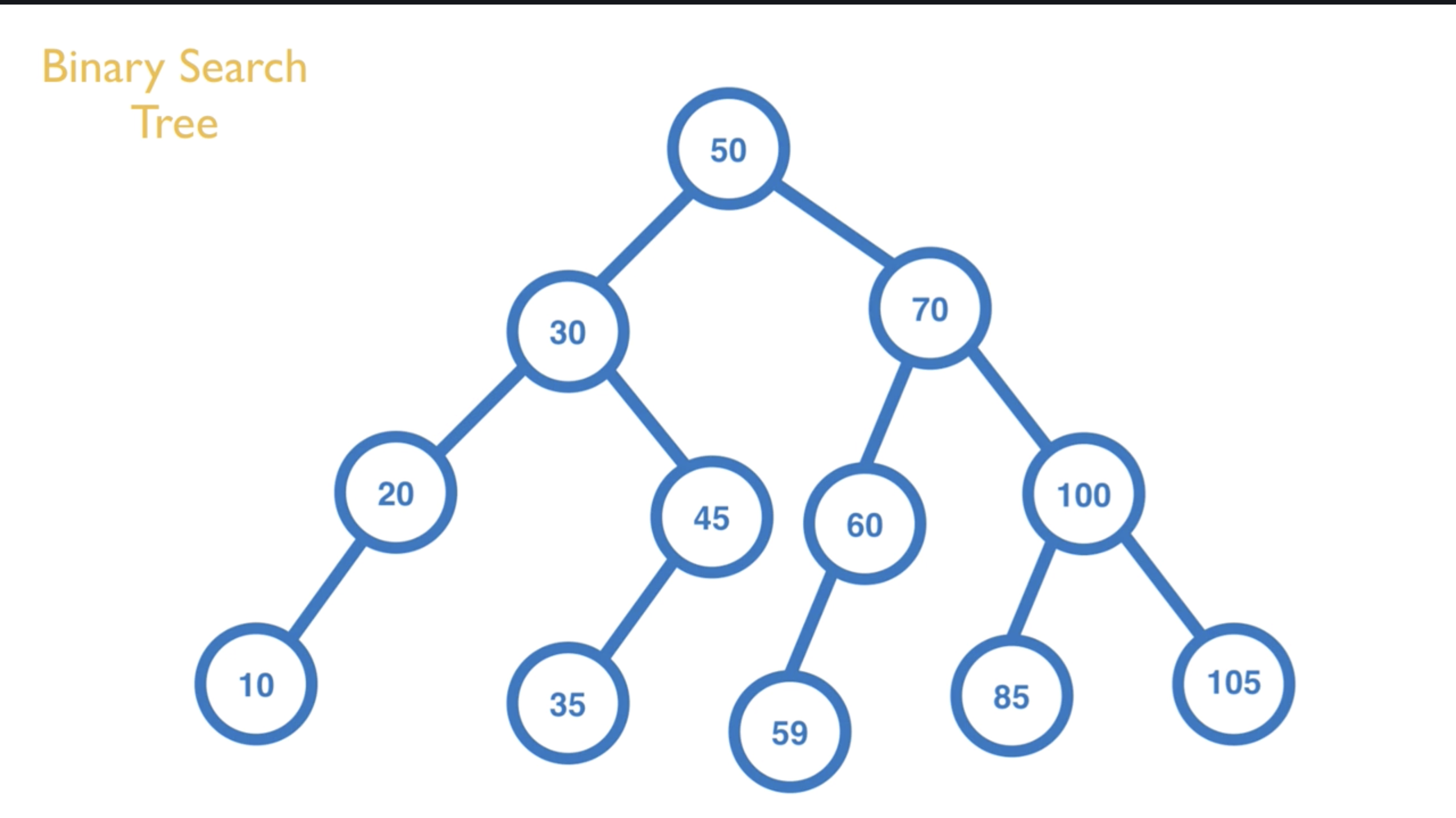
定义
- 每个 Node 会包含 value, left 和 right
- Binary Search Tree 会实作 lookup, insert, 和 remove 的方法
特性
- Perfect Binary Tree 有几个重要的特性:
- 每下一层的 Node 数量都是上一层 Node 数的两倍
- 最下层 Node 的数量会等于其上层所有 Node 数量加总后 + 1。例如,三层的 Perfect Tree,则三层 Node 的数量,会等同于前两层的数量加总后再加 1,也就是 4 = 3 + 1。
- Node 的总数量会同于 2 的(Node 层数)次方 -1,也就是 2^h - 1
- Binary Search Tree 有一个很重要的概念是,它是有「阶层(关係)」的概念在内,并不是把所有数字放在同一层排序。
时间複杂度 Time Complexity
| 操作 | Time Complexity 时间複杂度 |
|---|---|
| Lookup | O(log N) |
| Insert | O(log N) |
| Delete | O(log N) |
情境
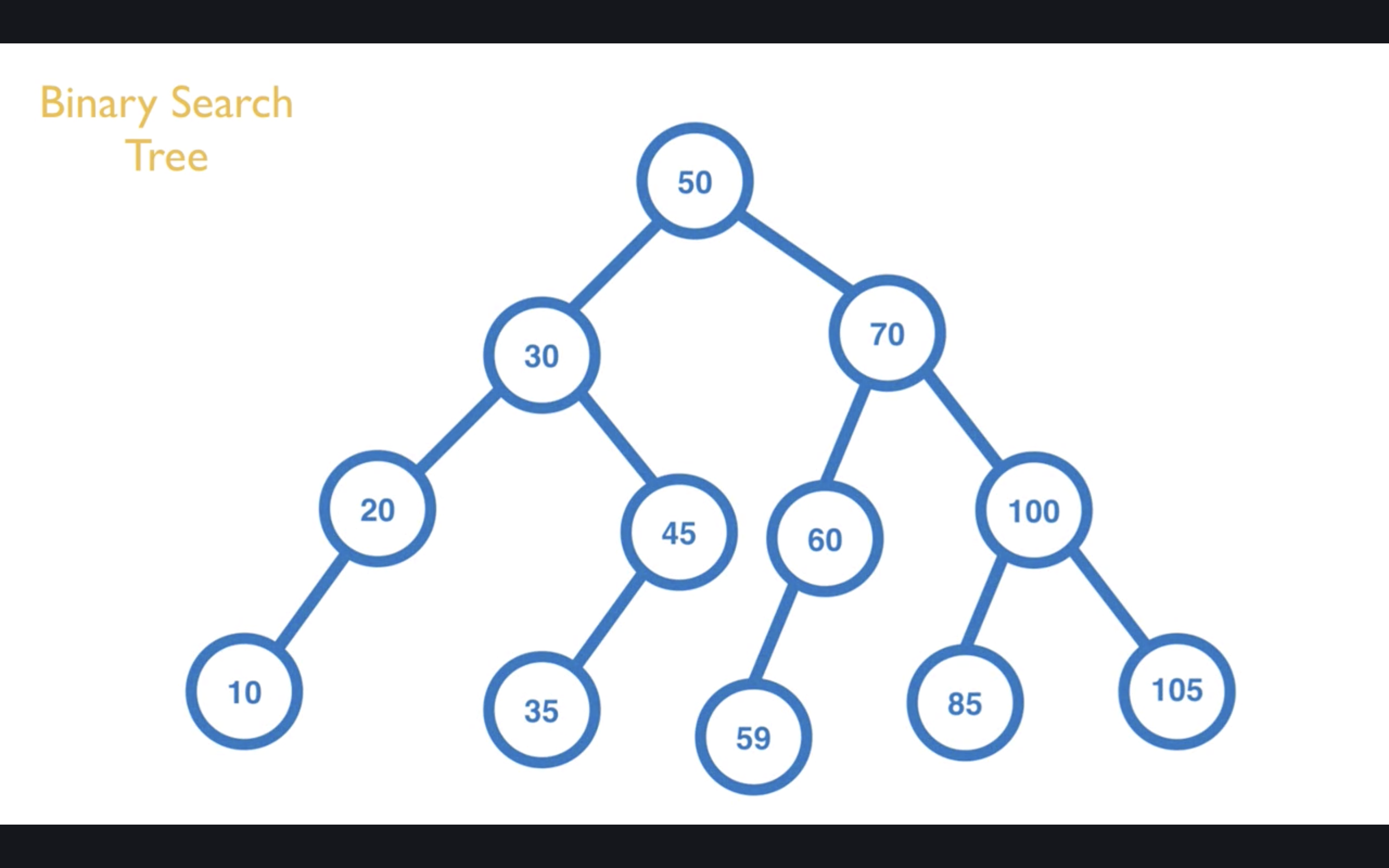
但使用它有一个很重要的前提是资料必须尽量平均分散在左右两边,让它长成一个树状结构,如果资料都是集中在某一侧的话,则不适合使用 Binary Search Tree。
这种资料结构常用在「字典」、「电话簿」、「使用者资料」等等。
Depth First Traversal
- 由小到大依序迭代(in-order)
- 由上往下,由左至右(pre-order)
- 由下往上,由左至右(post-order)
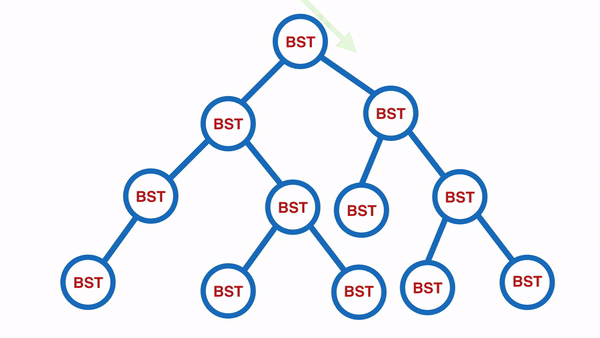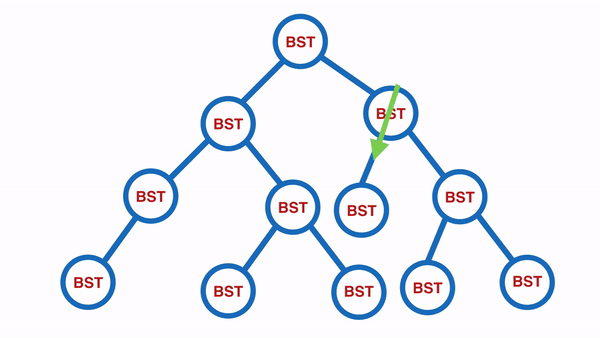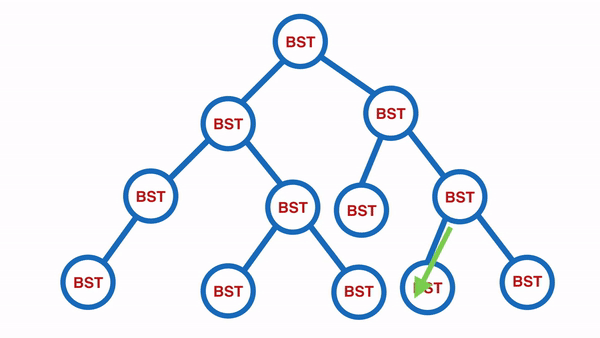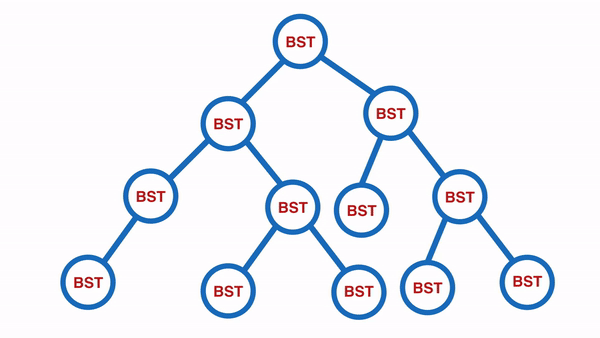
In-Order:由小到大依序迭代
从最底部开始,先把左边的输出,再输出右边的,如此所有的值就会由小到大依序排列。
输出的内容会是:[10, 20, 30, 35, 45, 50, 59, 60, 70, 85, 100, 105]。
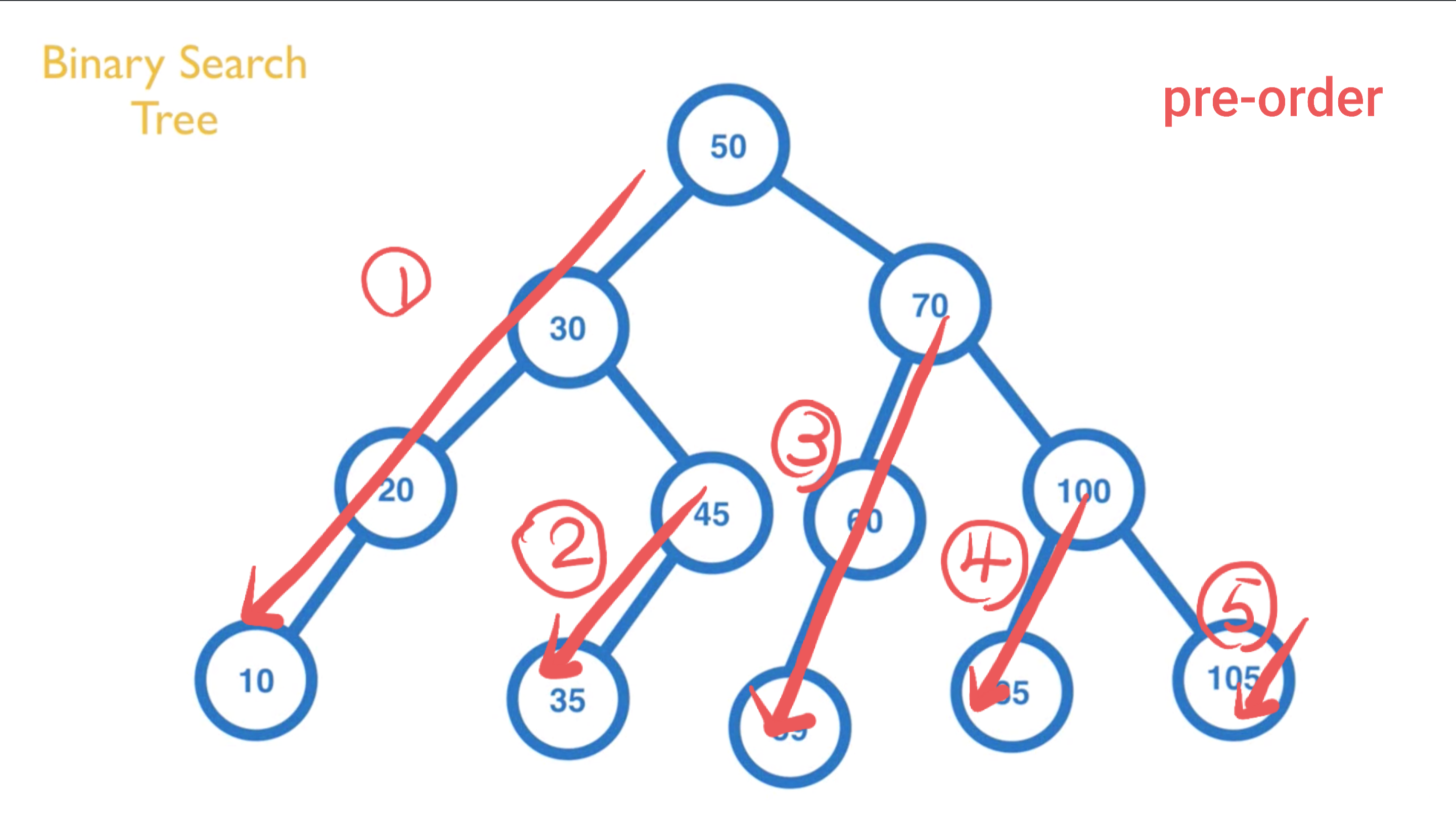
Pre-Order:由上往下,由左至右(中左右)
适合使用在想要 Copy Tree 时使用
由上往下,由左至右,依序输出所有内容。
以下图为例,会输出 [50, 30, 20, 10, 45, 35, 70, 60, 59, 100, 85, 105]
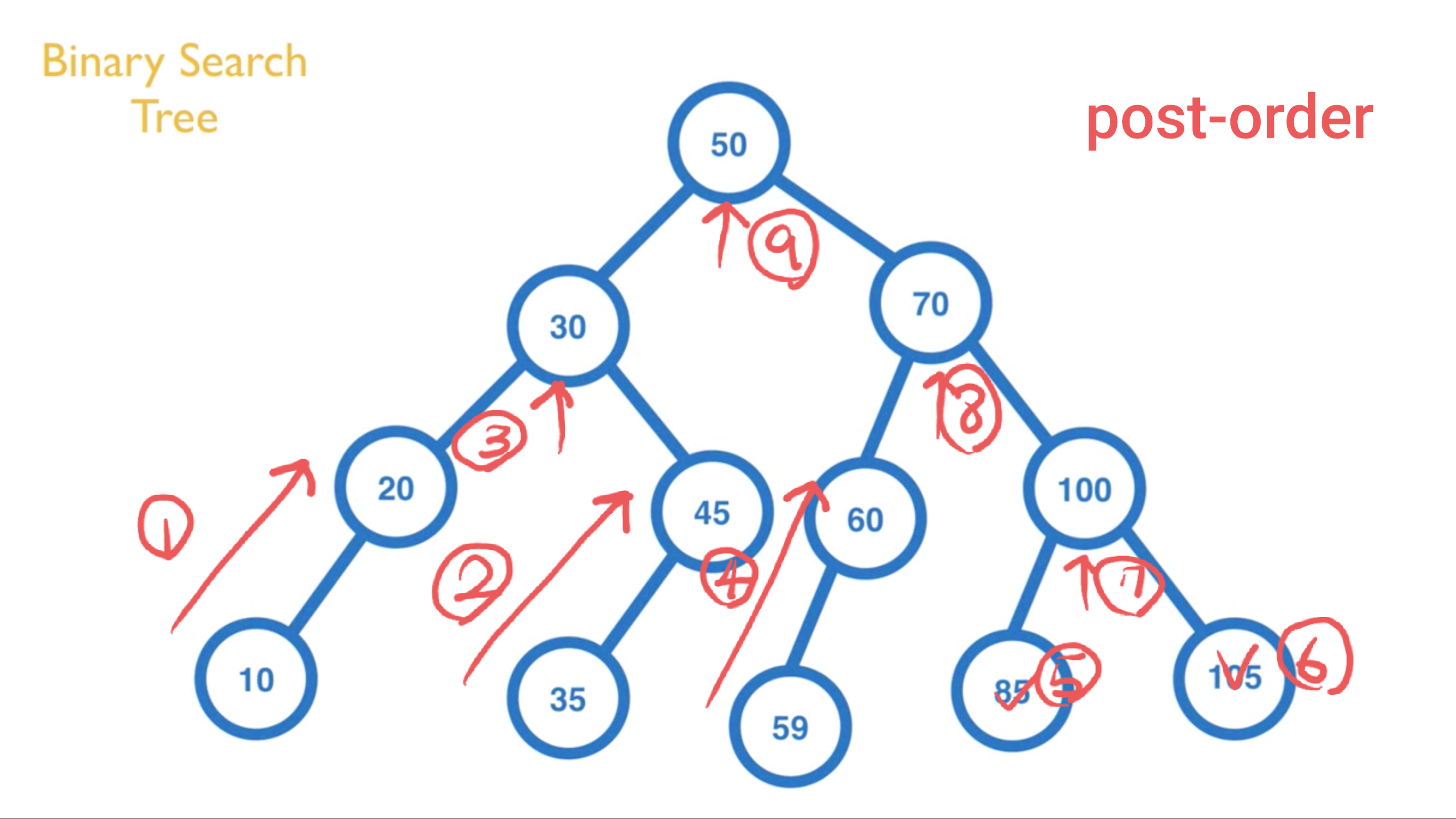
Post-Order:由下往上,由左至右(左右中)
适合使用在删除节点时,由下往上,由左至右
以下图为例,会输出 [10, 20, 35, 45, 30, 59, 60, 85, 105, 100, 70, 50]
Breadth First Traversal
适合用在有阶层性的资料,例如公司的组织架构,如此可以快速地找出管理职有谁,员工有谁等等
参考资料
Donate KJ 贊助作者喝咖啡
如果這篇文章對你有幫助的話,可以透過下面支付方式贊助作者喝咖啡,如果有什麼建議或想說的話可以贊助並留言給我
If this article has been helpful to you, you can support the author by treating them to a coffee through the payment options below. If you have any suggestions or comments, feel free to sponsor and leave a message for me!
| 方式 Method | 贊助 Donate |
| PayPal | https://paypal.me/kejyun |
| 綠界 ECPay | https://p.ecpay.com.tw/AC218F1 |
| 歐付寶 OPay | https://payment.opay.tw/Broadcaster/Donate/BD2BD896029F2155041C8C8FAED3A6F8 |